プレスリリース
国立研究開発法人海洋研究開発機構
国立大学法人京都大学
大規模な気候シミュレーションデータを効率的に探索・取得するシステム(SEAL)を開発
~都道府県単位の将来予測も簡単表示、温暖化適応策検討にも貢献~
1. 発表のポイント
- ◆
- 数ペタバイトの大規模な気候のシミュレーションデータから高速かつ効率的に必要な情報を抽出する技術を開発した。
- ◆
- 従来のシステムと比べて約1%の所要時間で必要な情報を抽出することが可能であり、専門的な知識がなくとも直感的に操作可能なインターフェースを採用している。
- ◆
- 将来の気候変動予測や影響評価などの研究が飛躍的に進むと期待されるとともに、地域ごとの温暖化適応策検討にも貢献すると期待される。
2. 概要
国立研究開発法人海洋研究開発機構(理事長 松永 是、以下「JAMSTEC」という。)付加価値情報創生部門情報エンジニアリングプログラムの中川 友進 特任技術副主幹及び国立大学法人京都大学(総長 山極 壽一)学術情報メディアセンタービジュアライゼーション研究分野の小山田 耕二 教授らは、文部科学省委託事業「気候変動適応技術社会実装プログラム(Social Implementation Program on Climate Change Adaptation Technology:SI-CAT)」の元で、数ペタバイトの大規模アンサンブル気候データ(※1)から高速かつ効率的に必要な情報を抽出する技術を開発しました。
「地球温暖化対策に資するアンサンブル気候予測データベース(d4PDF)」の解析は、気候変動予測やそれに伴う不確実性を定量評価するためにとても重要です。しかし、d4PDFのデータ量は約3ペタバイトと膨大です。これまで、従来のシステムではシミュレーションモデル名や変数名などシミュレーション前に決めた情報から検索しなくてはならず、情報の探索・取得には長時間を要し、また大容量の記録装置を備える必要があるなど高いハードルがありました。
そこで本研究では、シミュレーション後に得られる降水量や気温といった物理量を都道府県単位の空間情報にまとめ、時間的に圧縮し、必要なデータを効率的に検索・取得する技術を開発しました。この技術を実装したシステム「SI-CAT気候実験データベースシステム(System for Efficient content-based retrieval to Analyze Large volume climate data:SEAL、図1)」は、本プレスリリース後、文部科学省の事業で開発されているデータ統合・解析システム(DIAS)にて公開します。(図2)。
SEALの使用によって、従来のWebベースの検索システムと比べて、ユーザーがダウンロードするデータの容量は0.5%未満に、また必要なデータを見付けるまでの総時間は1%未満にまで減ることとなるため(図3)、今後は過去の顕著な気象イベントに対する要因分析、将来変化予測の不確実性の理解、影響評価などの研究が飛躍的に進むものと期待される(図4)ほか、ユーザーフレンドリーなインターフェースによって、研究者のみならず、各省庁、自治体、産業界等においても幅広く利用されるものと期待されます。
本成果は、公益社団法人日本地球惑星科学連合が発行する学術雑誌「Progress in Earth and Planetary Science」に2月26日付(日本時間)で掲載される予定です。
タイトル:Development of a System for Efficient Content-Based Retrieval to Analyze Large Volume of Climate Data
著者:中川友進1、尾上洋介2、川原慎太郎1、荒木文明1、小山田耕二3、松岡大祐1、石川洋一1、藤田実季子1、杉本志織1、岡田靖子1、川添祥4、渡辺真吾1、石井正好5、水田亮5、村田昭彦5、川瀬宏明5
所属:1. 国立研究開発法人海洋研究開発機構、2. 学校法人日本大学、3. 国立大学法人京都大学、4. 国立大学法人北海道大学、5. 気象庁気象研究所
3.背景
コンピュータの性能の向上に伴い、大規模アンサンブル気候データのデータサイズは急激に増加しています。例えばd4PDFのデータサイズは約3ペタバイトですが、過去のデータセットと比べて、非常に大きなデータサイズです。このような大規模アンサンブル気候データの系統的な解析は、確率的な気候変動の影響評価を行うために非常に重要です。しかし系統的な解析には、一般に高性能なコンピュータだけでなく大容量のデータ記憶装置が必要となります。ユーザーがd4PDFを自身のローカルコンピュータにダウンロードしようとすると、1)ユーザーのディスク容量の不足、2)長時間のダウンロード、3)データサーバーへの高い負荷、という問題が発生することから、個々の研究者による系統的な解析は困難になりつつあります。
現在、気候の研究分野ではDIAS(https://www.diasjp.net/)やWDCC(https://cera-www.dkrz.de/WDCC/ui/cerasearch/)など従来のWebベースの検索システムが活用されています。これら全ての従来システムは、シミュレーション後に得られる降水量や気温といった物理量を使用してデータを検索するようには設計されておらず、データファイルそのものに関連付けられているメタデータを使用してデータファイルを検索するように設計されており、前述の問題が発生します。そこで本研究では、物理量などデータファイルの内容に関連付けられているメタデータを使用してユーザーがデータファイルを検索・取得できる技術の開発を行いました。また、その技術を実装したシステムであるSEALをDIASから公開します。
4.成果
SEALは図1の概念図で示すようにリレーショナルデータベース(※2)、データ提供機能及びユーザーインターフェースで構成されています。リレーショナルデータベースは空間と時間で圧縮されたシミュレーションデータを格納しており、検索を効率的にする重要な役割を担っています。空間的な圧縮とは、20km四方で格子状に分割された領域データを47都道府県ごとにまとめることを指しています。また、降水量や気温といった物理量は時別値ではなく日別値、月別値または年別値を必要とすることから、47都道府県ごとに、降水量の積算や気温の平均を計算することで時間的な圧縮を行い格納しています。
データ提供機能は、ユーザーの検索結果に基づいて空間的・時間的に切り出されたデータを提供可能とします。多くのユーザーはテキスト形式やCSV形式などの人間が読める形式へ変換したデータを必要としていることから、バイナリデータ(コンピュータが直接的に処理するためのデータ)をテキスト形式またはCSV形式へ変換する機能を付与しています。
ユーザーはWebから簡易にデータ検索やダウンロードが可能なユーザーインターフェース(Web UI)を通じて本システムを利用可能です。Web UIは、条件に合うデータを見付けることを主な機能とした「SEAL-Finder(SEAL-F)」、データを分析および可視化することを主な機能とした「SEAL-Visualizer(SEAL-V)」で構成されています。図2はSEALのWeb UIのトップページのスクリーンショットであり、SEAL-FとSEAL-Vへアクセスするためのリンクが貼られています。ユーザーはSEAL-Fを使用すると検索の返り値を数値として取得することができ、またSEAL-Vを使用すると検索の返り値をヒストグラムなどの画像として取得することができます(図3)。
空間的・時間的に圧縮されたデータの圧縮率を計算したところ、空間的な圧縮率は北海道(302個の20km格子で構成)では1/302≒0.33%、東京都と大阪府(それぞれ13個の20km格子で構成)では1/13≒7.7%となりました。また、時間的な圧縮率は、時別値から日別値へ圧縮した場合は1/24≒4.2%となりました。そのため、空間的圧縮と時間的圧縮の両方を適用した場合、日別値のデータサイズは0.01~0.3%へと縮小されます。ケーススタディとして従来システムとSEALを使用した方法で必要なデータファイルを取得するまでの所要時間を定量的に調べたところ、図4の条件では1%未満となることを確認することができました。
従来、大規模アンサンブル気候データから必要なデータファイルを取得するには「ユーザーのディスク容量の不足」、「長時間のダウンロード」及び「データサーバーへの高い負荷」という問題がありましたが、本成果により、これら全ての問題を解決することが可能です。
5.今後の展望
SEALはd4PDFの利用を飛躍的に促進し、学術の発展へ貢献するとともに気候変動に関わる関連企業(コンサルタントなど)が自治体からの業務を請け負う際にSEALを利用することなども期待されます。
本成果により、複数の格子の物理量を予め積算し空間解像度を粗くすることで高速な検索を実現しましたが、今後は格子のそのままの物理量に対して高速な検索を実現する研究開発の方向性が重要となると考えています。SEALのために開発された技術は、他の研究分野におけるシミュレーションや観測のデータに対しても非常に有用だと考えられ、今後、様々な分野のビッグデータへの応用も期待されます。
【補足説明】
※1 アンサンブル気候データ:将来気候のシミュレーションを行う際に、初期値に少しばらつきを与えて複数回の計算を行なって作成したデータを意味する。
※2 リレーショナルデータベース:事前定義された相互関係を持つデータ項目の集まり。データ項目は、列と行を持つテーブルの組み合わせとして定義される。リレーショナルデータベースを使用すると、テーブル間の関係を事前に定義することにより複雑なデータの関係を扱うことができる。一般に、リレーショナルデータベースとの通信のインターフェースとしてStructured Query Language(SQL)が使用されている。PostgreSQLはリレーショナルデータベースを管理するためのシステムのこと。
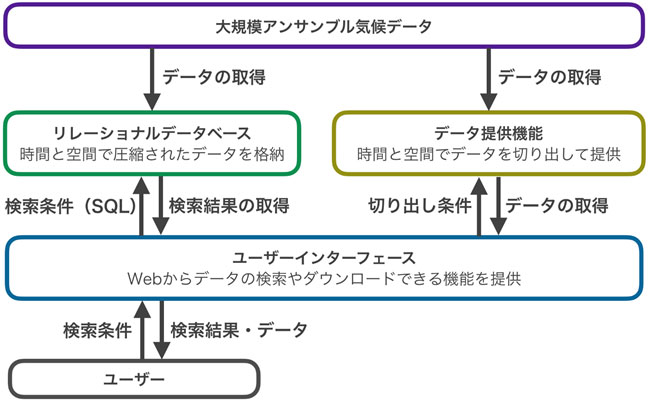
図1 SEALの概念図。

図2 SEALのWeb UIのトップページのスクリーンショット。
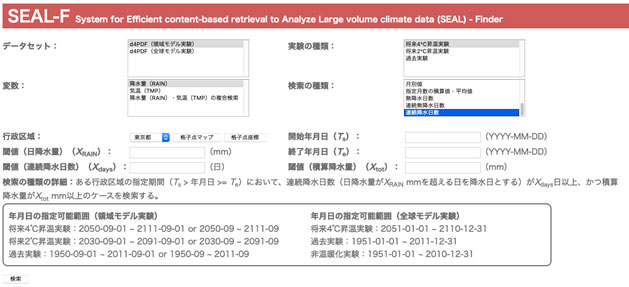
図3-1 SEAL-Fの検索ページ。データセット(領域モデル実験、全球モデル実験)、変数(降水量、気温、台風トラックデータ(全球モデル実験のみ))、実験の種類(領域モデルは将来4°C昇温実験・将来2°C昇温実験・過去実験の3種類、全球モデルは将来4°C昇温実験・過去実験・非温暖化実験の3種類)、検索の種類、および行政区域(47都道府県)やシミュレーション期間などの検索の種類ごとに設定された条件を指定する。検索の種類は、降水量ならば例えば3日間積算降水量、日降水量の年最大値や連続無降水日数といったものをリストから選択可能。気温ではある期間の平均気温、猛暑日日数や真冬日日数などを選ぶことができる。検索結果はSEAL-Vを用いると以下のように簡単にグラフ化できる。
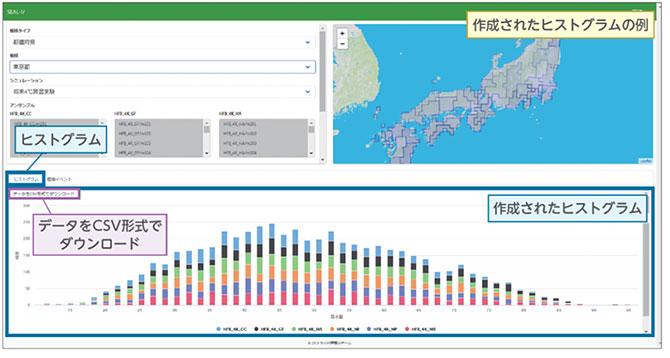
図3-2 SEAL-Vによるヒストグラム例。将来4°C昇温すると仮定した多数のシミュレーションデータを用いて、東京都の平均日降水量(mm/日)を作成している。
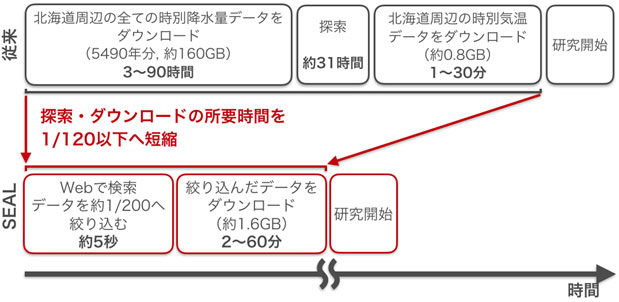
図4 SEALの予想される利点の概略図。図に示されている経過時間は、DIASからJAMSTECへのダウンロード速度(4〜120 Mbps)に基づく、将来4度昇温実験のデータを使用した際の実測値。
- (本研究について)
- 国立研究開発法人海洋研究開発機構
- 付加価値情報創生部門 情報エンジニアリングプログラム
特任技術副主幹 中川 友進 - 付加価値情報創生部門 情報エンジニアリングプログラム
主任技術研究員 荒木 文明 - 国立大学法人京都大学
- 学術情報メディアセンター・ビジュアライゼーション研究分野
教授 小山田 耕二 - (報道担当)
- 国立研究開発法人海洋研究開発機構
- 海洋科学技術戦略部 広報課
- 国立大学法人京都大学
- 総務部 広報課 国際広報室